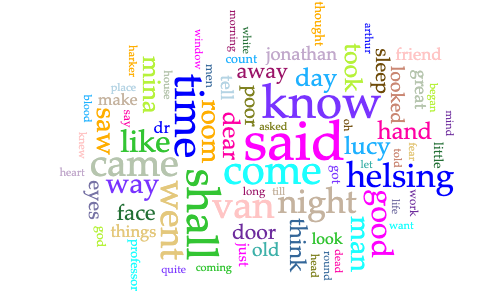This project was created by Natalie Kretschmer, Theodore Manning, Faihaa Khan, Nuraly Soltonbekov, and Brianna Caszatt for the ENGL 720 course Textual Studies in the Digital Age: Doing Things with Novels, Fall 2022 semester with Professor Jeff Allred.
The text of Dracula came from this edition in Project Gutenberg. Each post is numbered sequentially, in the order in which it appears in the text. There is an H2 at the beginning of each post making it clear whose point of view it was from (in some cases this did mean adding text where it did not exist in the original text, but we used the same wording that Bram Stoker used, e.g., “Jonathan Harker’s Journal (continued)”). Some journal and diary posts started with a date and then had entries marked as “Later” but of the same date; these all appear as one post. The exception is when an entry of the same date was was broken up by a new chapter, in which case the chapter breaks were preserved for this project.
Each post is categorized according to the chapter in which it appeared. Each post also has multiple tags. There are month and date tags, corresponding to the month and the date associated with each section of text. The posts are also tagged according to what type of text they are: journal and diary entries, letters, telegrams, memoranda and notes, ship’s log, and newspaper clippings. There are also tags corresponding to whose diary or journal the text came from: Jonathan’s journal, Mina’s journal, Dr. Seward’s diary, and Lucy’s diary And as there is much exchange of correspondence throughout the novel, so there are tags for each of the primary characters’ correspondence (including that which they sent and also received): Jonathan’s, Mina’s, Lucy’s, Dr. Seward’s, Van Helsing’s, Arthur’s, Quincy’s, and Dracula’s. There are also several instances in the story where correspondence is not delivered or received by the intended recipient, so there’s also a category for this: unopened or undelivered.
Google Ngram Viewer Results
Here are larger versions of the Google Ngram Viewer results shared in the annotations in post No. 3.
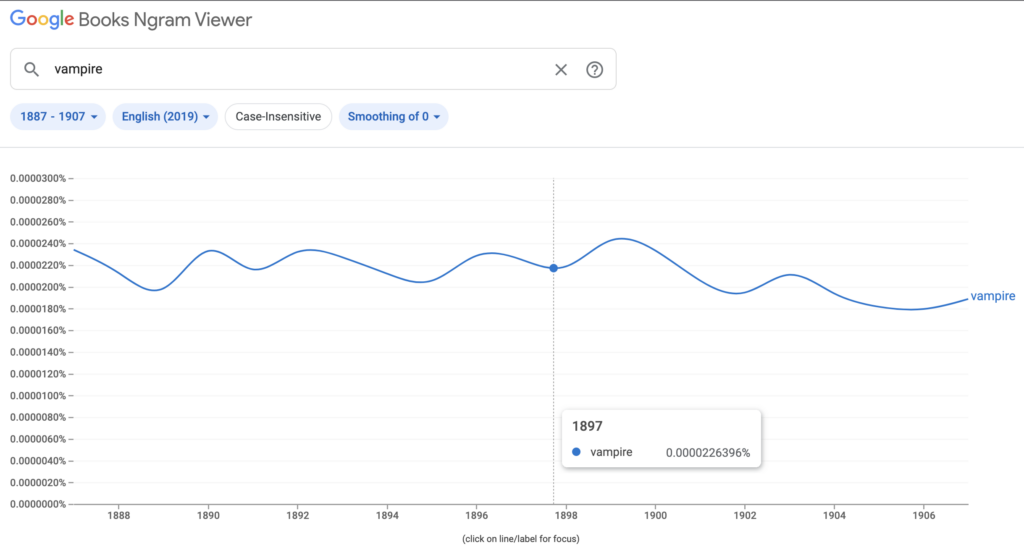
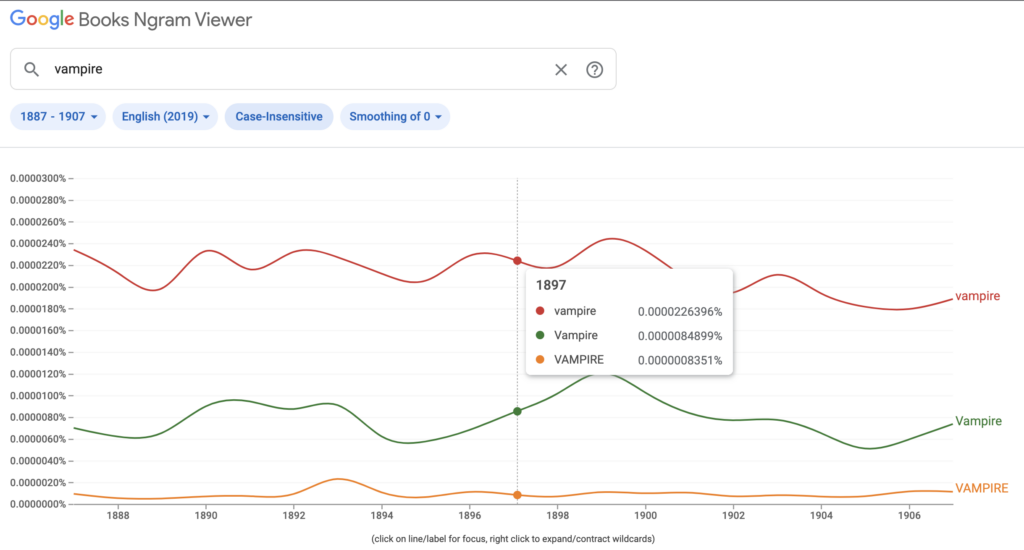
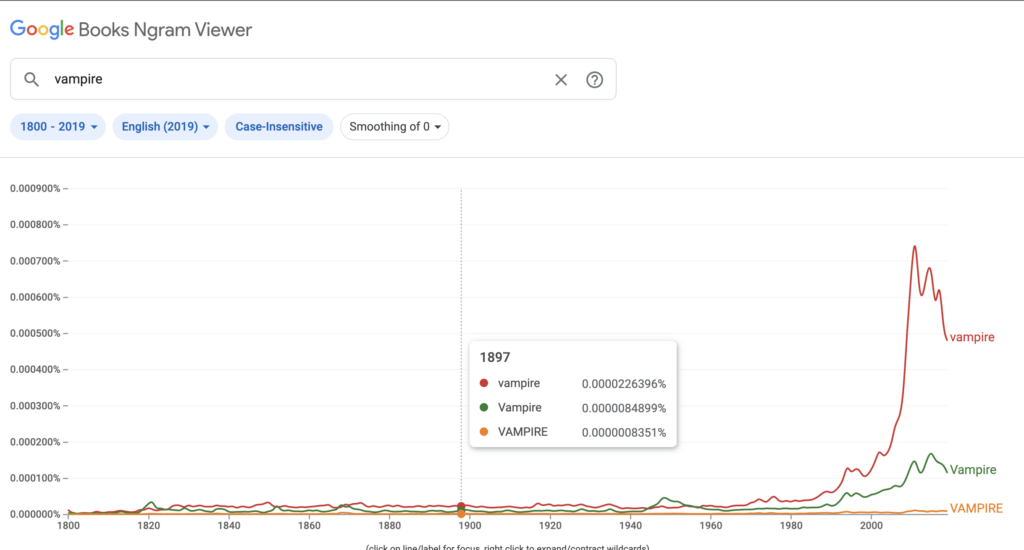
The incidence rate of vampire in 1897 in the Google Book corpus is 0.0000226396%, which is slightly less than in 1887 (0.0000234080%). The peak during this time (1887 to 1907, 10 years before and after the publication of Dracula) occurs during 1899 at 0.0000252876%, but the increased usage is not sustained over this time period.Between 1887 and 1907 (10 years before and after the publication of Dracula), the overall usage of all-capital VAMPIRE is low and steady, which is expected. Capital Vampire is used less than lowercase vampire, but the trend is overall the same, and I don’t think the line graphs support a case that the publication of Dracula greatly or consistently increased the usage of “vampire” in books (at least in the Google Book corpus).The usage of vampire in the Google Book corpus is also very small before and after Dracula is published compared with more present dates. Here is the incidence of vampire, Vampire, and VAMPIRE from 1800 to 2019 (the entirety of data available in the tool). Lowercase vampire incidence peaks in 2010 at 0.0006673093%; capital Vampire peaks in 2014 at 0.0001549446%.
Voyant Tools Word Cloud
Here is the word cloud I created in with Voyant Tools and shared in an annotation in post No. 1.
This Voyant word cloud shows the 75 most used words in Dracula, excluding stop words (see stop words here: https://voyant-tools.org/docs/#!/guide/stopwords). Out of 9,085 unique non-stop words, the top 5 most used words are “said” (used 570 times), “shall” (used 427 times), “know” (used 396 times), “time” (used 390 times), and “come” (used 339 times).
Python and the Natural Language Toolkit
In a Jupyter notebook using Python 3, I imported the text of Dracula from Project Gutenberg, and tokenized it into a list of words and punctuation. I then removed all of the punctuation and converted the list into NLTK so I could use the similar function and test out a multiple words from the novel. Here are screenshots for some of the more interesting results.
Using the similar function from NLTK, “beauty” is similar to: and, time, work, world, window, door, day, things, face, part, sight, knowledge, blood, trouble, facts, transfusion, pillar, next, morning, hourUsing the similar function from NLTK, “arouse” is similar to: be, do, you, make, take, give, harker, left, have, get, find, light, ask, move, see, pass, him, tell, effect, feelUsing the similar function from NLTK, “evil” is similar to: the, all, these, strange, men, jonathan, but, late, it, little, good, way, red, me, light, work, by, them, you, oldUsing the similar function from NLTK, “vampire” is similar to: morning, time, night, thing, house, count, door, room, table, sofa, tomb, belief, professor, and, way, library, window, water, more, longUsing the similar function from NLTK, “voluptuous” is similar to: danube, red, full, river, vampire, bright, dead, gleaming, narrow, open, charming, lovely, gloating, scarlet, mocking, harbour, wanton, positive
parchedUsing the similar function from NLTK, “red” is similar to: morning, time, the, my, light, day, long, full, coming, white, rest, best, eyes, dead, pain, left, next, hour, late, placeUsing the similar function in NLTK, “mist” is similar to: night, room, window, wolves, professor, door, day, others, rest, air, house, time, castle, count, other, fire, road, lock, morning, riverUsing the similar function from NLTK, “blood” is similar to: it, him, me, them, her, and, us, all, which, you, eyes, life, heart, dust, place, time, work, others, hand, wolvesUsing the similar function from NLTK, “garlic” is similar to: time, head, hand, place, way, door, room, eyes, fear, heart, tomb, anxiety, morning, east, books, light, work, castle, south, worldUsing the similar function in NLTK, “god” is similar to: you, the, it, me, her, he, him, his, us, my, this, them, all, and, she, hand, lucy, i, london, bedUsing the similar function from NLTK, “lips” is similar to: eyes, face, horses, hand, head, arms, cheeks, heart, throat, others, room, house, blood, feet, ship, left, way, work, count, bedUsing the similar function from NLTK, “throat” is similar to: eyes, face, heart, room, hand, place, head, neck, lips, life, forehead, soul, and,
time, sleep, door, diary, husband, work, love
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: